Problem
We have multiple Spark jobs running during ETL phase of our application. Some of them are really large and complicated jobs which takes hours to complete. One of such job, which uses GraphX & Pregal libraries, started failing after running for sometime. We use Spark History server to debug any jobs after they are completed and to our surprise information about only this job is missing in the history server. This puts us in deep trouble because we have no way to troubleshoot what happened or why the job is failing.
Spark History Server
Every SparkConext launches a web UI and displays useful information about the Spark job that is running currently. But the information displayed there is not persisted, means it will not be available after the job is completed. For that we have to enable event logs, which put the events Spark job emit to a persisted storage.
Spark’s another component History server can be started to load its UI from this persisted store which can be used to debug jobs that are completed, i.e. historic jobs. The persistence storage can be a Local file system, HDFS, S3 or anything that is supported by Hadoop APIs.
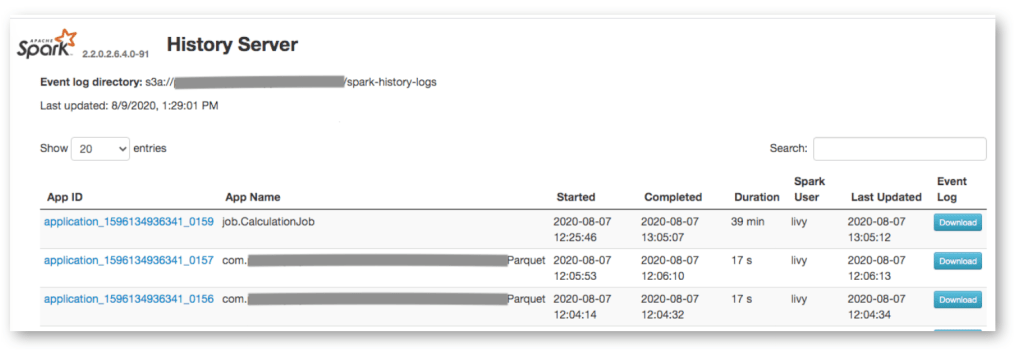
Our Setup
We have an ephemeral spark cluster which scales out to 10s of slave nodes during ETL and scale in to a few slave nodes after ETL. Read this if you are interested to know more about how we do this. Event logging is enabled & we are using S3 as our persistent storage. This is done using the following two spark configurations.
spark.eventLog.enabled = true
spark.eventLog.dir = s3a://xyz-bucket/spark-history-logs
History server is running on the Spark master node. It is configured to use the same events directory as it’s log directory from where it display the data in UI.
spark.yarn.historyServer.address = spark-cluster-master-address:18080
spark.history.fs.logDirectory = s3a://xyz-bucket/spark-history-logs
History server is started by running the following command from Spark installation directory.
./sbin/start-history-server.sh

Back to the problem
So we are able to see all the completed jobs & their logs in the history server but only this one job was missing. It was the longest job we have in our ETL phase. Apparently there is a known issue with streaming logs of long running jobs to eventual consistent store like S3 as explained here.
Solution
One solution is to switch to HDFS as the event logs directory. Since ours is an ephemeral cluster we should create an HDFS directory which does not use the elastic nodes which are destroyed during scale-in. But as a general practice in our project, we use S3 or RDS for any persistence store and do not prefer storing anything like this in an EC2 node.
The other solution was to put the event logs into an HDFS directory only for this job and once the job is completed, move the logs to S3. This can be achieved by overriding the event logs directory by supplying a runtime configuration for the job.
spark.eventLog.dir : hdfs://spark-cluster-master-address/eventLogDir/
Once the job is completed, copy the contents inside this directory to S3.
hdfs dfs -copyToLocal hdfs://spark-cluster-master-address/eventLogDir/ /tmp/eventLogDir/
aws s3 cp /tmp/eventLogDir/ s3://xyz-bucket/spark-history-logs/

We are able to see the spark job and it’s logs in history server after this. I am sure there would be other solutions to this problem. If you have faced similar problems in your application, please let me know how did you solve it.
Discover more from Anil G Kurian
Subscribe to get the latest posts sent to your email.
